В наши дни база данных MySQL используется уже практически везде, где только можно. Невозможно представить сайта, который бы работал без MySQL. Конечно, есть некоторые исключения, но основную часть рынка занимает именно эта система баз данных. И самая популярная из реализаций - MariaDB. Когда проект небольшой, для его работы достаточно одного сервера, на котором расположены все службы: веб-сервер, сервер баз данных и почтовый сервер. Но когда проект становится более большим может понадобится выделить для каждой службы отдельный сервер или даже разделить одну службу на несколько серверов, например, MySQL.
Для того чтобы поддерживать синхронное состояние баз данных на всех серверах одновременно нужно использовать репликацию. В этой статье мы рассмотрим как настраивается репликация MySQL с помощью MariaDB Galera Cluster.
ЧТО ТАКОЕ MARIADB GALERA?
MariaDB Galera - это кластерная система для MariaDB типа master-master. Начиная с MariaDB 10.1 программное обеспечение Galera Server и MariaDB Server поставляются в одном пакете, так что вы получаете все необходимое программное обеспечение сразу. На данный момент MariaDB Galera может работать только с движками баз данных InnoDB и XtraDB. Из преимуществ использования репликации можно отметить добавление избыточности для базы данных сайта. Если одна из баз данных, даст сбой, то вы сразу же сможете переключиться на другой. Все сервера поддерживают синхронизированное состояние между собой и гарантируют отсутствие потерянных транзакций.
Основные возможности MariaDB Galera:
- Репликация с постоянной синхронизацией;
- Автоматическое объединение узлов;
- Возможность подключения нескольких узлов master;
- Поддержка записи на любой из узлов;
- Прозрачная параллельная репликация;
- Масштабируемость чтения и записи, минимальные задержки;
- Давшие сбой ноды автоматически отключаются от кластера;
- Нельзя блокировать доступ к таблицам.
НАСТРОЙКА РЕПЛИКАЦИИ MYSQL
В этой инструкции мы будем использовать для примера Ubuntu 16.04 и MariaDB версии 10.1. Перед тем, как начать полностью обновите систему:
sudo apt-get update -y
sudo apt-get upgrade -y
Поскольку мы будем развертывать нашу конфигурацию на нескольких узлах, нужно выполнить операции обновления на всех них. Если сервер баз данных MariaDB еще не установлен, его нужно установить. Сначала добавьте репозиторий и его ключ:
sudo apt-key adv --recv-keys --keyserver hkp://keyserver.ubuntu.com:80 0xF1656F24C74CD1D8
sudo add-apt-repository "deb http://ftp.utexas.edu/mariadb/repo/10.1/ubuntu xenial main"
sudo apt-get update -y
Когда обновление списка пакетов завершено, установите MariaDB командой:
sudo apt install mariadb-server rsync -y
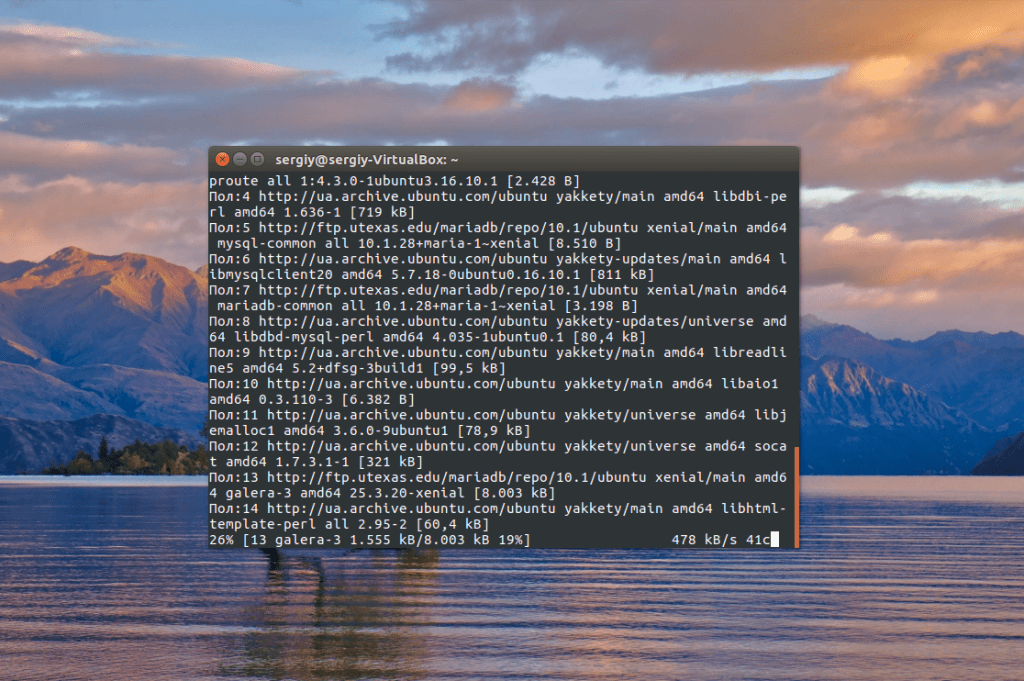
Пакет rsync нам понадобится для выполнения непосредственно синхронизации. Когда установка будет завершена, вам необходимо защитить базу данных с помощью скрипта mysql_secure_installation:
sudo mysql_secure_installation

По умолчанию разрешен гостевой вход, есть тестовая база данных, а для пользователя root не задан пароль. Все это надо исправить. Читайте подробнее в статье . Если кратко, то вам нужно будет ответить на несколько вопросов:
Enter current password for root (enter for none):
Change the root password? n
Remove anonymous users? Y
Disallow root login remotely? Y
Remove test database and access to it? Y
Reload privilege tables now? Y
Когда все будет готово, можно переходить к настройке нод, между которыми будет выполняться репликация баз данных mysql. Сначала рассмотрим настройку первой ноды. Можно поместить все настройки в my.cnf, но лучше будет создать отдельный файл для этих целей в папке /etc/mysql/conf.d/.
Добавьте такие строки:
binlog_format=ROW
innodb_autoinc_lock_mode=2
bind-address=0.0.0.0
wsrep_on=ON
wsrep_sst_method=rsync
# Galera Node Configuration
wsrep_node_address="192.168.56.101"
wsrep_node_name="Node1"

Здесь адрес 192.168.56.101 - это адрес текущей ноды. Дальше перейдите на другой сервер и создайте там такой же файл:
sudo vi /etc/mysql/conf.d/galera.cnf
binlog_format=ROW
default-storage-engine=innodb
innodb_autoinc_lock_mode=2
bind-address=0.0.0.0
# Galera Provider Configuration
wsrep_on=ON
wsrep_provider=/usr/lib/galera/libgalera_smm.so
# Galera Cluster Configuration
wsrep_cluster_name="galera_cluster"
wsrep_cluster_address="gcomm://192.168.56.101,192.168.56.102"
# Galera Synchronization Configuration
wsrep_sst_method=rsync
# Galera Node Configuration
wsrep_node_address="192.168.56.102"
wsrep_node_name="Node2"

Аналогично тут адрес ноды - 192.168.0.103. Остановимся на примере с двумя серверами, так как этого достаточно чтобы продемонстрировать работу системы, а добавить еще один сервер вы можете, прописав дополнительный IP адрес в поле wsrep_cluster_address. Теперь рассмотрим что означают значения основных параметров и перейдем к запуску:
- binlog_format - формат лога, в котором будут сохраняться запросы, значение row сообщает, что там будут храниться двоичные данные;
- default-storage-engine - движок SQL таблиц, который мы будем использовать;
- innodb_autoinc_lock_mode - режим работы генератора значений AUTO_INCREMENT;
- bind-address - ip адрес, на котором программа будет слушать соединения, в нашем случае все ip адреса;
- wsrep_on - включает репликацию;
- wsrep_provider - библиотека, с помощью которой будет выполняться репликация;
- wsrep_cluster_name - имя кластера, должно соответствовать на всех нодах;
- wsrep_cluster_address - список адресов серверов, между которыми будет выполняться репликация баз данных mysql, через запятую;
- wsrep_sst_method - транспорт, который будет использоваться для передачи данных;
- wsrep_node_address - ip адрес текущей ноды;
- wsrep_node_name - имя текущей ноды.
Настройка репликации MySQL почти завершена. Остался последний штрих перед запуском - это настройка брандмауэра. Сначала включите инструмент управления правилами iptables в Ubuntu - UFW:
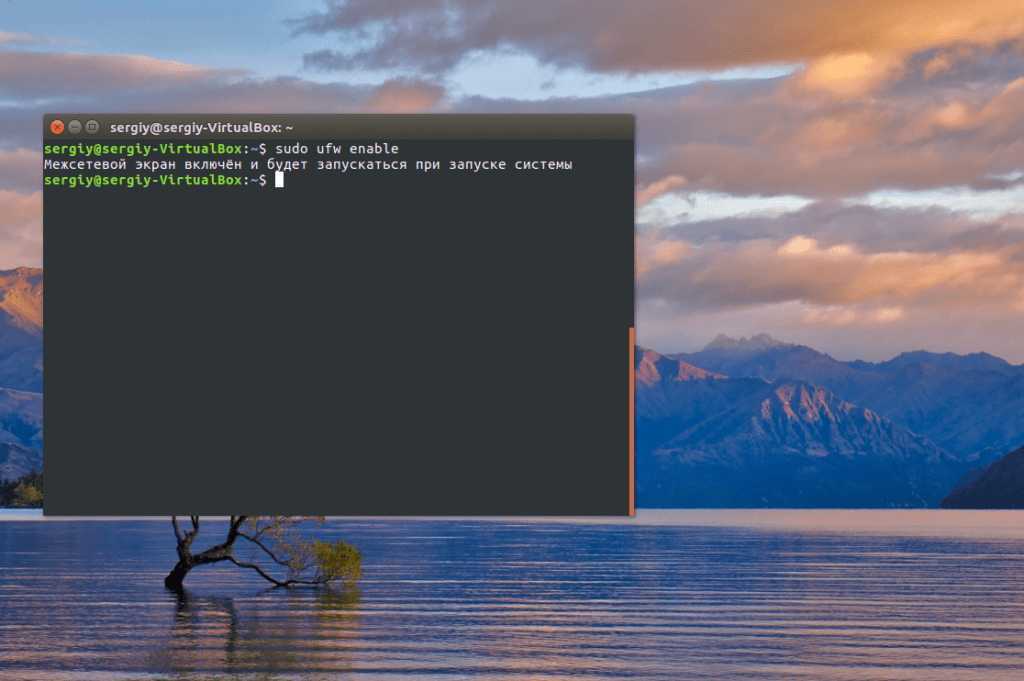
Затем откройте такие порты:
sudo ufw allow 3306/tcp
sudo ufw allow 4444/tcp
sudo ufw allow 4567/tcp
sudo ufw allow 4568/tcp
sudo ufw allow 4567/udp

ЗАПУСК MARIADB GALERA
После успешной настройки всех нод нам останется только запустить кластер Galera на первой ноде. Перед тем как мы сможем запустить кластер, вам нужно убедиться, что сервис MariaDB остановлен на всех серверах:
sudo galera_new_cluster

Проверить запущен ли кластер и сколько к нему подключено машин можно командой:

Сейчас там только одна машина, теперь перейдите на другой сервер и запустите ноду там:
sudo systemctl start mysql
Вы можете проверить прошел ли запуск успешно и были ли какие-либо ошибки командой:
sudo systemctl status mysql

Затем, выполнив ту же команду, вы убедитесь, что новая нода была автоматически добавлена к кластеру:
mysql -u root -p -e "show status like "wsrep_cluster_size""

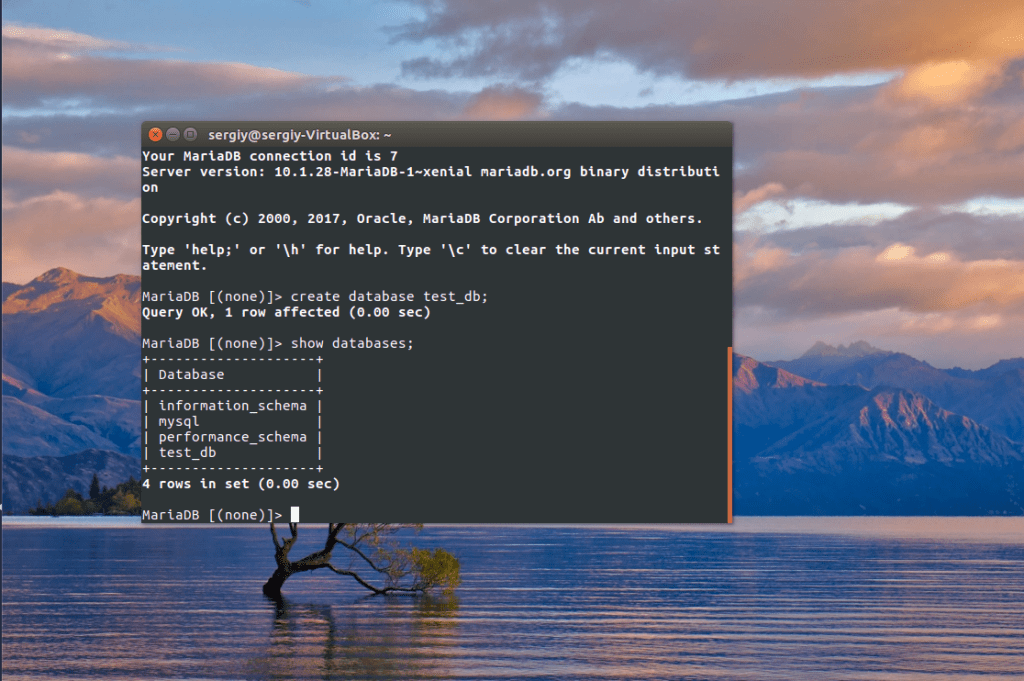
Чтобы проверить как работает репликация просто создайте базу данных на первой ноде и посмотрите действительно ли она была добавлена на всех других:
mysql -u root -p
MariaDB [(none)]> create database test_db;
MariaDB [(none)]> show databases;
mysql -u root -p
MariaDB [(none)]> show databases;

Как видите, действительно база данных автоматически появляется на другой машине. Репликация данных mysql работает.
Материал из Linux Wiki
Настройка репликации
Мастер-сервер
- my.cnf на мастер-сервере:
[ mysqld] # Идентификатор сервера. На каждой связке серверов (как на мастерах, так и на слейвах) должен быть уникален. # Является числом в диапазоне от 1 до 4294967295 (2 ^32 -1 ) server-id = 1 # Путь к бинарным логам, в которых сохраняются все изменения в базе данных мастер-сервера. Должно быть достаточно места под эти логи log-bin = /var/lib/mysql/mysql-bin # Сколько дней хранить бинарные логи на мастере. В некотором роде это еще и определяет, на сколько слейв может отстать от мастера # expire_logs_days = 10 # Размер файла бинлога (каждого отдельного файла) # max_binlog_size = 1024M # Включаем сжатие пересылаемых на Slave логов slave_compressed_protocol = 1 # Имя базы, для которой надо делать репликацию. При необходимости делать репликацию нескольких баз - повторить опцию с нужным именем базы replicate-do-db = testdb # Помимо этой опции, есть еще опции "обратного выбора" - для исключения выборки баз # replicate-ignore-db= database_name # а также опции для репликации отдельных таблиц (аналогично - выбрать одну/несколько; исключить одну/несколько, а также определение имен через wildcard"ы) # Эта опция нужна на тот случай, если этот мастер-сервер является слейвом по отношению к другому - чтобы слейв для данного мастера (суб-слейв основного мастера) тоже получал обновления # Может пригодиться при репликации мастер-мастер с одним слейвом # log-slave-updates
- Даем права слейв-серверу делать репликацию с этого. Для этого в консоли mysql даем команду:
mysql> GRANT replication slave ON * .* TO "repluser" @"replhost" IDENTIFIED BY "replpass" ;
- repluser - имя пользователя для подключения. Пользователь создается в момент выполнения команды.
- replhost - IP-адрес или домен хоста слейв-сервера, который будет подключаться к этому мастеру и импортировать с него изменения.
- replpass - пароль для подключения
Перезапускаем сервер, после чего в консоли можно выполнить команду
mysql> SHOW MASTER STATUS ;
которая покажет файл бинарного лога, с которым сейчас работает мастер и текущую позицию в логе, а также базу/базы, для которых делается репликация.
Slave-сервер
- Добавляем нужные опции в конфиге my.cnf на slave-сервере:
[ mysqld] # Идентификатор сервера для данной связки серверов - см. описание выше server-id = 2 # Relay-логи - логи, скачанные с мастер-сервера # Указываем путь для этих логов; должно быть достаточно места для их хранения. # relay-log = /var/lib/mysql/mysql-relay-bin # relay-log-index = /var/lib/mysql/mysql-relay-bin.index # Имя базы, которую будем реплицировать replicate-do-db = testdb # Включаем сжатие пересылаемых на Slave логов slave_compressed_protocol = 1
Перезапускаем сервер для применения изменений
Запуск репликации
На мастере блокируем таблицы на запись для получения полностью корректного дампа:
mysql> FLUSH TABLES WITH READ LOCK ; mysql> SET GLOBAL read_only = ON ;
Сливаем дамп с сервера. Кое-где обычно еще пишут про то, что необходимо смотреть позицию и имя лога на мастере - это не обязательно и решается ключом --master-data для mysqldump, который запишет необходимую информацию в сам дамп:
mysqldump --master-data -hmasterhost -umasteruser -pmasterpass masterdbname > dump.sql
После этого пускаем мастер в работу:
mysql> SET GLOBAL read_only = OFF;
(хотя возникает мысль - а действительно ли нужно лочить базу при дампе? Как только начал делаться дамп с --master-data - в него кидается имя лога и позиция, а таблицы автоматически лочатся на запись - т.е. все то же самое, только в автоматическом режиме)
mysql -hslavehost -uslaveuser -pslavepass slavedbname < dump.sql
В данном случае slavedbname = masterdbname, хотя при желании можно сделать так, чтобы база реплицировалась уже под другим именем.
Указываем слейву адрес мастер-сервера:
mysql> CHANGE MASTER TO MASTER_HOST = "masterip" , MASTER_USER = "repluser" , MASTER_PASSWORD = "replpass" ;
где masterip - IP-адрес или домен мастер-сервера, а остальные опции - те, что указывались выше при настройке мастера. Имя лог-файла и позиция берется из дампа, но при желании их можно вручную указать через опции MASTER_LOG_FILE = "имя_лога", MASTER_LOG_POS = позиция
После этой команды информация о мастере сохраняется в файле master.info в каталоге баз данных mysql-сервера. При желании можно указать эти опции в конфиге слейв-сервера:
master-host = masterip master-user = repluser master-password = replpass master-port = 3306
После этого запускаем slave-сервер через mysql-консоль:
mysql> START SLAVE;
Теперь можно проверить статус slave-сервера командой
mysql> SHOW SLAVE STATUS ;
Из интересной информации там могут быть поля:
- Slave_IO_State: Waiting FOR master TO send event , Slave_IO_Running: Yes и Slave_SQL_Running: Yes - все работает хорошо:)
- Seconds_Behind_Master - на сколько слейв отстал от мастера. В нормальном режиме должен быть 0, однако 0 при реальном отставании может быть и в том случае, если на мастере производится много изменений, а канал между мастером и слейвом узкий и последний не успевает скачивать бинлоги с мастера. В таком случае "0" корректен, но лишь для того, что успело скачаться из логов.
И прочая текущая информация вроде отсутствия ошибок, текущей позиции и имени лога сервера, лога слейва и т.п.
Разное
Для mysqldump есть 2 опции для вписывания имени лога и позиции в файл дампа: --master-data и --dump-slave . Вторая есть не везде:
root@import:~# mysqldump --help | grep "dump-slave" root@import:~# mysqldump --version mysqldump Ver 10.13 Distrib 5.1.61, for portbld-freebsd8.2 (amd64)
Dump-slave[=value] This option is similar to --master-data except that it is used to dump a replication slave server to produce a dump file that can be used to set up another server as a slave that has the same master as the dumped server. It causes the dump output to include a CHANGE MASTER TO statement that indicates the binary log coordinates (file name and position) of the dumped slave"s master (rather than the coordinates of the dumped server, as is done by the --master-data option). These are the master server coordinates from which the slave should start replicating. This option was added in MySQL 5.5.3.
Соответственно, одна опция - для клонирования слейва, вторая - для создания субслейва. Иначе говоря, dump-slave позволяет в цепочке master-slave1-slave2 создать (с помощью slave1) еще один slave1 (в дамп запишется позиция в логе и файл лога относительно логов master), master-data позволяет создать slave2 - в дамп запишется позиция/лог относительно бинлогов slave1.
Ошибки репликации
При работе репликации могут возникать ошибки - по какой-либо причине, например, ручном внесении данных на слейв-сервере.
Варианты решения.
С репликацией серверов MySQL я познакомился относительно недавно, и по мере проведения разных опытов с настройкой, записывал, что у меня получалось. Когда материала набралось достаточно много, появилась идея написать эту статью. Я постарался собрать советы и решения по некоторым самым основным вопросам, с которыми я столкнулся. По ходу дела я буду давать ссылки на документацию и другие источники. Не могу претендовать на полноту описания, но надеюсь, что статья будет полезной.
Небольшое введение
Репликация (от лат. replico -повторяю) — это тиражирование изменений данных с главного сервера БД на одном или нескольких зависимых серверах. Главный сервер будем называть мастером , а зависимые — репликами .Изменения данных, происходящие на мастере, повторяются на репликах (но не наоборот). Поэтому запросы на изменение данных (INSERT, UPDATE, DELETE и т. д.) выполняются только на мастере, а запросы на чтение данных (проще говоря, SELECT) могут выполняться как на репликах, так и на мастере. Процесс репликации на одной из реплик не влияет на работу других реплик, и практически не влияет на работу мастера.
Репликация производится при помощи бинарных логов , ведущихся на мастере. В них сохраняются все запросы, приводящие (или потенциально приводящие) к изменениям в БД (запросы сохраняются не в явном виде, поэтому если захочется их посмотреть, придется воспользоваться утилитой mysqlbinlog). Бинлоги передаются на реплики (бинлог, скачанный с мастера, называется "relay binlog ") и сохраненные запросы выполняются, начиная с определенной позиции. Важно понимать, что при репликации передаются не сами измененные данные, а только запросы, вызывающие изменения.
При репликации содержимое БД дублируется на нескольких серверах. Зачем необходимо прибегать к дублированию? Есть несколько причин:
- производительность и масштабируемость . Один сервер может не справляться с нагрузкой, вызываемой одновременными операциями чтения и записи в БД. Выгода от создания реплик будет тем больше, чем больше операций чтения приходится на одну операцию записи в вашей системе.
- отказоустойчивость . В случае отказа реплики, все запросы чтения можно безопасно перевести на мастера. Если откажет мастер, запросы записи можно перевести на реплику (после того, как мастер будет восстановлен, он может принять на себя роль реплики).
- резервирование данных . Реплику можно «тормознуть » на время, чтобы выполнить mysqldump, а мастер - нет.
- отложенные вычисления . Тяжелые и медленные SQL-запросы можно выполнять на отдельной реплике, не боясь помешать нормальной работе всей системы.
Настройка репликации
Допустим, у нас есть работающая база данных MySQL, уже наполненная данными и включенная в работу. И по одной из причин, описанных выше, мы собираемся включить репликацию нашего сервера. Наши исходные данные:- IP-адрес мастера 192.168.1.101, реплики — 192.168.1.102.
- MySQL установлен и настроен
- требуется настроить репликацию БД testdb
- мы можем приостановить работу мастера на некоторое время
- у нас, разумеется, есть root на обеих машинах
Настройки мастера
Обязательно укажем уникальный ID сервера, путь для бинарных логов и имя БД для репликации в секции :server-id = 1
log-bin = /var/lib/mysql/mysql-bin
replicate-do-db = testdb
Убедитесь, что у вас достаточно места на диске для бинарных логов.
Добавим пользователя replication, под правами которого будет производится репликация. Будет достаточно привилегии "replication slave ":
mysql@master> GRANT replication slave ON "testdb".* TO "replication"@"192.168.1.102" IDENTIFIED BY "password";
Перезагрузим MySQL, чтобы изменения в конфиге вступили в силу:
root@master# service mysqld restart
Если все прошло успешно, команда "show master status " должна показать примерно следующее:
mysql@master> SHOW MASTER STATUS\G
File: mysql-bin.000003
Position: 98
Binlog_Do_DB:
Binlog_Ignore_DB:
Значение position должно увеличиваться по мере того, как вносятся изменения в БД на мастере.
Настройки реплики
Укажем ID сервера, имя БД для репликации и путь к relay-бинлогам в секции конфига, затем перезагрузим MySQL:server-id = 2
relay-log = /var/lib/mysql/mysql-relay-bin
relay-log-index = /var/lib/mysql/mysql-relay-bin.index
replicate-do-db = testdb
Root@replica# service mysqld restart
Переносим данные
Здесь нам придется заблокировать БД для записи. Для этого можно либо остановить работу приложений, либо воспользоваться установкой флажка read_only на мастере (внимание: на пользователей с привилегией SUPER этот флаг не действует). Если у нас есть таблицы MyISAM, сделаем также "flush tables ":mysql@master> FLUSH TABLES WITH READ LOCK;
mysql@master> SET GLOBAL read_only = ON;
Посмотрим состояние мастера командой «show master status» и запомним значения File и Position (после успешной блокировки мастера они не должны изменятся):
File: mysql-bin.000003
Position: 98
Делаем дамп БД, и после завершения операции снимаем блокировку мастера:
mysql@master> SET GLOBAL read_only = OFF;
Переносим дамп на реплику и восстанавливаем из него данные.
Наконец, запускаем репликацию командами "change master to " и "start slave " и посмотрим, все ли прошло хорошо:
mysql@replica> CHANGE MASTER TO MASTER_HOST = "192.168.1.101 ", MASTER_USER = "replication ", MASTER_PASSWORD = "password ", MASTER_LOG_FILE = "mysql-bin.000003 ", MASTER_LOG_POS = 98;
mysql@replica> start slave;
Значения MASTER_LOG_FILE и MASTER_LOG_POS мы берем с мастера.
Посмотрим, как идет репликация командой "show slave status ":
mysql@replica> SHOW SLAVE STATUS\G
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.1.101
Master_User: replication
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000003
Read_Master_Log_Pos: 98
Relay_Log_File: mysql-relay-bin.001152
Relay_Log_Pos: 235
Relay_Master_Log_File: mysql-bin.000003
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB: testdb,testdb
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 98
Relay_Log_Space: 235
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 5
Наиболее интересные сейчас значения я выделил. При успешном начале репликации их значения должны быть примерно такими, как в листинге (см. описание команды "show slave status " в документации). Значение Seconds_Behind_Master может быть любым целым числом.
Если репликация идет нормально, реплика будет следовать за мастером (номер лога в Master_Log_File и позиция Exec_Master_Log_Pos будут расти). Время отставания реплики от мастера (Seconds_Behind_Master), в идеале, должно быть равно нулю. Если оно не сокращается или растет, возможно, что нагрузка на реплику слишком высока — она просто не успевает повторять изменения, происходящие на мастере.
Если же значение Slave_IO_State пусто, а Seconds_Behind_Master равно NULL, репликация не началась. Смотрите лог MySQL для выяснения причины, устраняйте её и заново запускайте репликацию:
mysql@replica> start slave;
Путем этих нехитрых действий мы получаем реплику, данные которой идентичны данным на мастере.
Кстати, время блокировки мастера — это время создания дампа. Если он создается недопустимо долго, можно попробовать поступить так:
- заблокировать запись в мастер флагом read_only, запомнить позицию и остановить MySQL.
- после этого скопировать файлы БД на реплику и включить мастер.
- начать репликацию обычным способом.
Добавляем реплики
Пусть у нас уже есть работающие мастер и реплика, и нам нужно добавить к ним еще одну. Сделать это даже проще, чем добавить первую реплику к мастеру. И гораздо приятнее то, что нет необходимости останавливать для этого мастер.Для начала настроим MySQL на второй реплике и убедимся, что мы внесли нужные параметры в конфиг:
server-id = 3
replicate-do-db = testdb
Теперь остановим репликацию на первой реплике:
mysql@replica-1> stop slave;
Реплика продолжит работать нормально, однако данные на ней уже не будут актуальными. Посмотрим статус и запомним позицию мастера, до которой реплика дошла перед остановкой репликации:
mysql@replica-1> SHOW SLAVE STATUS\G
Нам нужные будет значения Master_Log_File и Exec_Master_Log_Pos:
Master_Log_File: mysql-bin.000004
Exec_Master_Log_Pos: 155
Создадим дамп БД и продолжим репликацию на первой реплике:
mysql@replica-1> START SLAVE;
Восстановим данные из дампа на второй реплике. Затем включим репликацию:
mysql@replica-2> CHANGE MASTER TO MASTER_HOST = "192.168.1.101 ", MASTER_USER = "replication ", MASTER_PASSWORD = "password ", MASTER_LOG_FILE = "mysql-bin.000004 ", MASTER_LOG_POS = 155;
mysql@replica-2> START SLAVE;
Значения MASTER_LOG_FILE и MASTER_LOG_POS — это соответственно значения Master_Log_File и Exec_Master_Log_Pos из результата команды «show slave status » на первой реплике.
Репликация должна начаться с той позиции, на которой была остановлена первая реплика (и соответственно, создан дамп). Таким образом, у нас будет две реплики с идентичными данными.
Объединяем реплики
Иногда возникает такая ситуация: на мастере существует две БД, одна из которых реплицируется на одной реплике, а вторая — на другой. Как настроить репликацию двух БД на обеих репликах, не делая их дампы на мастере и не выключая его из работы? Достаточно просто, с использованием команды "start slave until ".Итак, у нас имеется master с базами данных testdb1 и testdb2, которые реплицируются соответственно на репликах replica-1 и replica-2. Настроим репликацию обеих БД на replica-1 без остановки мастера.
Остановим репликацию на replica-2 командой и запомним позицию мастера:
mysql@replica-2> STOP SLAVE;
mysql@replica-2> SHOW SLAVE STATUS\G
Master_Log_File: mysql-bin.000015
Exec_Master_Log_Pos: 231
Создадим дамп БД testdb2 и возобновим репликацию (на этом манипуляции с replica-2 закончились). Дамп восстановим на replica-1.
Ситуация на replica-1 такая: БД testdb1 находится на одной позиции мастера и продолжает реплицироваться, БД testdb2 восстановлена из дампа с другой позиции. Синхронизируем их.
Остановим репликацию и запомним позицию мастера:
mysql@replica-1> STOP SLAVE;
mysql@replica-1> SHOW SLAVE STATUS\G
Exec_Master_Log_Pos: 501
Убедимся, что в конфиге на replica-1 в секции указано имя второй БД:
replicate-do-db = testdb2
Перезагрузим MySQL, чтобы изменения в конфиге вступили в силу. Кстати, можно было просто перезагрузить MySQL, не останавливая репликацию — из лога мы бы узнали, на какой позиции мастера репликация остановилась.
Теперь проведем репликацию с позиции, на которой была приостановлена replica-2 до позиции, на которой мы только что приостановили репликацию:
mysql@replica-1> CHANGE MASTER TO MASTER_HOST = "192.168.1.101 ", MASTER_USER = "replication ", MASTER_PASSWORD = "password ", MASTER_LOG_FILE = "mysql-bin.000015 ", MASTER_LOG_POS = 231;
mysql@replica-1> start slave until MASTER_LOG_FILE = "mysql-bin.000016 ", MASTER_LOG_POS = 501;
Репликация закончится, как только реплика дойдет до указанной позиции в секции until, после чего обе наши БД будут соответствовать одной и той же позиции мастера (на которой мы остановили репликацию на replica-1). Убедимся в этом:
mysql@replica-1> SHOW SLAVE STATUS\G
mysql@replica-1> START SLAVE;
Master_Log_File: mysql-bin.000016
Exec_Master_Log_Pos: 501
Добавим в конфиг на replica-1 в секции имена обеих БД:
replicate-do-db = testdb1
replicate-do-db = testdb2
Важно: каждая БД должна быть указана на отдельной строке.
Перезагрузим MySQL и продолжим репликацию:
mysql@replica-1> CHANGE MASTER TO MASTER_HOST = "192.168.1.101 ", MASTER_USER = "replication ", MASTER_PASSWORD = "password ", MASTER_LOG_FILE = "mysql-bin.000016 ", MASTER_LOG_POS = 501;
После того, как replica-1 догонит мастер, содержание их БД будет идентично. Объединить БД на replica-2 можно или подобным образом, или сделав полный дамп replica-1.
Рокировка мастера и реплики
Переключить реплику в режим мастера бывает необходимо, например, в случае отказа мастера или при проведении на нем технических работ. Для возможности такого переключения необходимо настроить реплику подобно мастеру, или сделать её пассивным мастером .Включим ведение бинарных логов (дополнительно к relay-бинлогам) в конфиге в секции :
log-bin = /var/lib/mysql/mysql-bin
И добавим пользователя для ведения репликации:
mysql@master> GRANT replication slave ON ’testdb’.* TO ’replication’@’192.168.1.101′ IDENTIFIED BY "password ";
Пассивный мастер ведет репликацию как и обычная реплика, но кроме этого создает бинарные логии — то есть, мы можем начать репликацию с него. Убедимся в этом командой "show master status ":
mysql@replica> SHOW MASTER STATUS\G
File: mysql-bin.000001
Position: 61
Binlog_Do_DB:
Binlog_Ignore_DB:
Теперь, чтобы перевести пассивный мастер в активный режим, необходимо остановить репликацию на нем и включить репликацию на бывшем активном мастере. Чтобы в момент переключения данные не были утеряны, активный мастер
необходимо заблокировать на запись.
mysql@master> FLUSH TABLES WITH READ LOCK
mysql@master> SET GLOBAL read_only = ON;
mysql@replica> STOP SLAVE;
mysql@replica> SHOW MASTER STATUS;
File: mysql-bin.000001
Position: 61
mysql@master> CHANGE MASTER TO MASTER_HOST = "192.168.1.102 ", MASTER_USER = "replication ", MASTER_PASSWORD = "password ", MASTER_LOG_FILE = "mysql-bin.000001 ", MASTER_LOG_POS = 61;
mysql@master> start slave;
Все, так мы поменяли активный мастер. Можно снять с бывшего мастера блокировку.
Заключение
Мы немного разобрались в том, как настраивать репликацию в MySQL и выполнять некоторые основные операции. К сожалению, за рамками статьи остались следующие важные вопросы:
- устранение единичных точек отказа (SPF, Single Points of Failure). При использовании единственного сервера MySQL, его отказ приводил к отказу всей системы. При использовании нескольких серверов, отказ любого из них приведет к отказу системы, если только мы специально не позаботимся об этом. Нам нужно предусмотреть обработку ситуации с отказом мастера и реплики. Одно из существующих средств — MMM , однако, требует доработки напильником.
- балансировка нагрузки. При использовании нескольких реплик нам было бы удобно использовать прозрачный механизм балансировки, особенно если производительность реплик неодинакова. Под Linux возможно использовать стандартное решение — LVS .
- изменение логики работы приложения. В идеальной ситуации, запросы на чтение данных надо направлять на реплики, а на изменение — на мастер. Однако, из-за возможного отставания реплик, такая схема часто неработоспособна и необходимо выявлять такие запросы на чтение, которые все же должны выполнятся на мастере.
Спасибо за внимание!
Репликация - механизм синхронизации содержимого нескольких копий объекта. Под этим процессом понимается копирование данных из одного источника на множество других и наоборот.
Обозначения:
- master - главный сервер, данные которого необходимо дублировать;
- replica - починенный сервер, хранящий копию данных главного
Для настройки репликации в MySQL необходимо выполнить ниже описанную последовательность действий, но это не догма и параметры могут изменяться в зависимости от обстоятельств.
На главном сервере отредактируем файл файл my.cnf, в секцию mysqld добавить строки:
Server-id = log-bin = mysql-bin log-bin-index = mysql-bin.index log-error = mysql-bin.err relay-log = relay-bin relay-log-info-file = relay-bin.info relay-log-index = relay-bin.index expire_logs_days=7 binlog-do-db =
- - уникальный идентификатор сервера MySQL, число в диапазоне 2 (0-31)
- - имя базы, информация о которой будет писаться в бинарный журнал, если баз несколько, то для каждой необходима отдельная строка с параметром binlog_do_db
На подчиненном отредактируем файл файл my.cnf, в секцию mysqld добавить строки:
Server-id = master-host = master master-user = replication master-password = password master-port = 3306 relay-log = relay-bin relay-log-info-file = relay-log.info relay-log-index = relay-log.index replicate-do-db =
На главном сервере добавим пользователя replication с правами на репликацию данных:
GRAANT REPLICATION SLAVE ON *.* TO "replication"@"replica" IDENTIFIED BY "password"
Заблокируем реплицируемые базы на главном сервере от изменения данных, программно или с помощью функционала MySQL:
Mysql@master> FLUSH TABLES WITH READ LOCK; mysql@master> SET GLOBAL read_only = ON;
Для разблокировки используется команда:
Mysql@master> SET GLOBAL read_only = OFF;
Сделаем резервные копии всех баз данных на главном сервере (или тех которые нам необходимы):
Root@master# tar -czf mysqldir.tar.gz /var/lib/mysql/
или средствами утилиты mysqldump:
Root@master# mysqldump -u root -p --lock-all-tables > dbdump.sql
Остановим оба сервера (в отдельных случаях можно обойтись и без этого):
Root@master# mysqlamdin -u root -p shutdown root@replica# mysqlamdin -u root -p shutdown
Восстановим реплицируемые базы данных на подчиненном сервере с помощью копирования директории. Перед началом репликации базы данных должны быть одинаковы:
Root@replica# cd /var/lib/mysql root@replica# tar -xzf mysqldir.tar.gz
или функционала mysql, тогда mysql на подчиненном сервере не было необходимости останавливать:
Root@replica# mysql -u root -p < dbdump.sql
Запустим mysql на главном сервере (а затем - на подчиненном, если это необходимо):
Root@master# /etc/init.d/mysql start root@replica# /etc/init.d/mysql start
Проверим работы главного и подчиненного серверов:
Mysql@replica> start slave; mysql@replica> SHOW SLAVE STATUS\G mysql@master> SHOW MASTER STATUS\G
На подчиненном сервере проверить логи в файле master.info, там должны содержаться запросы на изменение данных в базе. Так этот файл бинарный необходимо сначала преобразовать его в текстовый формат:
Root@replica# mysqlbinlog master.info > master_info.sql
При возникновении ошибок, можно использовать команды:
Mysql@replica> stop slave; mysql@replica> RESET SLAVE; mysql@master> RESET MASTER;
и повторить все действия начиная с блокировки баз данных.
Для горячего добавления серверов репликации можно исользовать синтаксис:
Mysql@replica> SHOW SLAVE STATUS\G mysql@master> SHOW MASTER STATUS\G mysql@replica-2> CHANGE MASTER TO MASTER_HOST = "master", MASTER_USER ="replication ", MASTER_PASSWORD = "password ", MASTER_LOG_FILE ="mysql-bin.000004 ", MASTER_LOG_POS = 155; mysql@replica-2> START SLAVE;
Информация из статусов покажет позицию и имя текущего файла лога.
В случае асинхронной репликации обновление одной реплики распространяется на другие спустя некоторое время, а не в той же транзакции. Таким образом, при асинхронной репликации вводится задержка, или время ожидания, в течение которого отдельные реплики могут быть фактически неидентичными. Но у данного вида репликации есть и положительные моменты: главному серверу не надо беспокоится о синхронизации данных, можно блокировать базу (например, для создания резервной копии) на подчиненной машине, без проблем для пользователей.
Список использованный источников
- Habrahabr.ru - Основы репликации в MySQL (http://habrahabr.ru/blogs/mysql/56702/)
- Википедия (http://ru.wikipedia.org/wiki/Репликация_(вычислительная_техника))
При полном или частичном использовании любых материалов с сайта вы обязаны явным образом указывать ссылку на в качестве источника.
Для успешного использования репликации в MySQL необходимо:
- Убедится, что на сервер, выступающий в роли Slave, установлена версия MySQL >= версии, установленной на Master. Репликация возможна и в обратном порядке, с Master с более новой версией на Slave с более старой, но работоспособность такого варианта не гарантируется.
- Проверить подключение со Slave-сервера MySQL на Master (# mysql -hMASTERHOST -uroot -p), так как оно может быть закрыто в firewall.
Master-slave репликация одной базы MySQL
Это простой пример master-slave репликации одной базы MySQL . Тем кто это делает впервые, следует начать с этого примера и в точности соблюдать инструкции.
Для начала, нужно прописать различные id для Master и Slave серверов. На Master-сервере нужно включить бинарный журнал (log-bin), указать БД для репликации и создать пользователя подчиненного сервера, через которого slave-сервер будет получать данные с master`а. На slave-сервере включается релейный лог (relay-log), указывается БД для репликации и запускается slave-репликация.
MASTER: действия, выполняемые на Master-сервере MySQL.
Отредактировать my.cnf - конфигурационный файл MySQL. Его месторасположение зависит от операционной системы и настроек самой MySQL. В my.cnf, в секции добавляются такие параметры:
server-
id=
1
# Путь к бинарному логу.
# Записывается название файла, без расширения, так как расширение все равно будет установлено
# MySQL-сервером автоматически (.000001, .000002 и т.д.)
# Располагать mysql-bin желательно в корне директории, где хранятся все БД,
# во избежание проблем с правами доступа.
log-
bin
=/
var/
lib/
mysql/
mysql-
bin
# Название БД MySQL, которая будет реплицироваться
После модификации my.cnf следует перезапустить MySQL. В директории для хранения журнала бинарных логов (log-bin) должен появиться один или несколько файлов mysql-bin.000001, mysql-bin.000002, ... .
Теперь нужно подключиться к MySQL как пользователь с максимальными правами и создать пользователя (rpluser_s500) с паролем (заменить PASSW), через которого Slave-сервер будет получать данные об обновлениях БД:
mysql>
GRANT
replication slave ON
*
.*
TO
"rpluser_
s500"
@"%
"
IDENTIFIED BY "PASSW"
;
mysql>
FLUSH PRIVILEGES
;
$ mysqldump -- master- data - hHOST - uUSER - p dbreplica > dbreplica.sql
Дамп можно снимать с БД под нагрузкой, но следует учесть, что если БД большая, то на время записи дампа БД будет не доступна на запись.
SALVE: действия, выполняемые на Slave-сервере MySQL.
Первым делом нужно провести правки my.cnf в секции :
# Идентификатор Master сервера (число от 1 до 4294967295)
server-
id=
500
# Путь к релей-логу, в котором хранятся данные, полученные от Master-сервера
# Требования такие же, как и к бинарному логу.
relay-
log
=/
var/
lib/
mysql/
mysql-
relay-
bin
relay-
log-
index
=/
var/
lib/
mysql/
mysql-
relay-
bin
.index
# Имя базы, в которую будут записываться все изменения,
# происходящие в БД с тем же именем на Master-сервере
replicate-
do-
db=
"dbreplica"
После модификации my.cnf - перезапустить MySQL.
mysql> CREATE DATABASE dbreplica
Теперь в неё нужно залить дамп:
$ mysql - uROOT - p dbreplica < dbreplica.sql
Далее настраиваем подключение к Master-серверу, где MASTER_HOSTNAME_OR_IP заменяется на адрес или ip MySQL master сервера, а MASTER_USER и PASSWORD - учетные данные пользователя, созданного на Master-сервере для подключения со Slave:
mysql> CHANGE MASTER TO MASTER_HOST = "MASTER_ HOSTNAME_ OR_ IP" , MASTER_USER = "rpluser_ s500" , PASSWORD = "PASSW" ;
После запуска этого запроса, в директории, где хранятся БД, создается файл master.info, куда записываются данные о подключении к Master.
Теперь, для начала репликации осталось отправить запрос к MySQL:
mysql> START SLAVE;
После этого, если все прошло успешно, можно наблюдать, как все изменения в БД на Master-сервере, появляются в БД на Slave.
Настройки репликации MySQL
Настройки бинарного лог-файла (log-bin)
Бинарный лог MySQL используется для ведения журнала изменений, происходящих в базах данных сервера. Для репликации он должен быть обязательно включен на Master-сервере, на Slave-серверах его стоит использовать, только если Slave является одновременно и Master`ом для другой подчиненной MySQL. Log bin включается, путем добавления параметра в mysql.cnf, секции :
log- bin = mysql- bin
В примере настроек: "Master-slave репликация одной базы MySQL" был включен бинарный лог для всех баз данных MySQL. Если нужно вести лог только для определенных БД, например DB_NAME1 и DB_NAME2 в my.cnf мастера нужно добавить опции binlog-do-db :
binlog-
do-
db=
"DB_
NAME1"
binlog-
do-
db=
"DB_
NAME2"
То есть нужно перечислить все наименования БД, где для каждой БД своя строка с параметром binlog-do-db. Антонимом этого оператора является binlog-ignore-db ="DB_NAME", который указывает MySQL, что нужно заносить в лог все базы данных, кроме тех, что указанны в параметрах binlog-ignore-db.
Если указать базы данных, через запятую, например так:
Неправильное использование параметра binlog-ignore-db!
binlog- ignore- db= "DB_ NAME3, DB_ NAME4"
то на первый взгляд все будет работать как нужно - никаких ошибок нет, но на самом деле, базы DB_NAME3 и DB_NAME4 не будут исключены из бинарного журнала: MySQL будет считать, что "DB_NAME3, DB_NAME4" это одна база данных с именем "DB_NAME3, DB_NAME4" (т.е. в имени БД находится запятая и пробел)!
Перед включением или исключением базы данных из бинарного лога, нужно понять, как и в каких режимах работает бинарный журнал MySQL. От этого зависит, на сколько надежно будет работать репликация, консистентность данных, и кол-во возникающих при её осуществлении ошибок (вплоть до полного их исключения).
Параметр, отвечающий за формат хранения данных бинарным журналом - binlog_format , который начиная с версии MySQL 5.1 может принимать 3 значения: STATEMENT (используется по умолчанию в MySQL = 5.7.7) и MIXED.
STATEMENT - режим бинарного лога MySQL
STATEMENT - в этом режиме в бинарный лог записываются обычные sql-запросы на добавление, обновление и удаление информации с дополнительными служебными данными. Открыв такой лог в текстовом редакторе, можно найти в нем запросы на изменение данных в БД в текстовом формате. Преимущества использования binlog_format=STATEMENT: сравнительно небольшой размер файла, возможность просматривать лог в mysqlbinlog или PHPMyAdmin`е. Недостатки же таятся в использовании SQL-запросов, подробнее об этом ниже.
Предположим, что в бинарный лог добавляются данные только для одной БД c названием users (binlog- do- db= "users" ). Следующий запрос, который непосредственно затрагивает базу данных "users", не попадет в бинарный журнал:
Пример № 1
USE
clients;
UPDATE
users.accounts SET
amount=
amount+
5
;
Такое поведение вызвано тем, что по умолчанию используется БД "clients", которая не логируется в бинарном журнале в режиме Statement.
Другой пример, когда запрос к БД, которая не указана в binlog-do-db, попадает в бинарный журнал:
Пример № 2
USE
users;
UPDATE
clients.discounts SET
percentage=
percentage+
5
;
Так происходит все так же, из-за использования базы данных по умолчанию, но в этом случае в бинарный журнал записываются "не те", "лишние" запросы.
И первый и второй запрос может привести к неожиданным последствиям, при использовании репликации на Slave сервере. В случае запроса из первого примера, данные на Master и Slave серверах будут различаться: на мастере amount=amount+5 выполнено, на Slave - нет. При использовании второго запроса, на Slave будет отправлен запрос на изменение данных в БД, которая не прописана в списке подчиненных, и Master-Slave репликация: завершится с ошибкой, если БД clients не существует на слейве или... внесет изменения в таблицу базы данных, если таковая есть. Таким образом, при Master-Slave репликации в режиме бинарного лога Statement, можно внести изменения в базу данных подчиненного сервера, которая не предназначалась для репликации! К каким последствиям может привести такие изменения, можно только догадываться, так что нужно быть очень осторожным, используя режим бинарного лога Statement.
Еще одна проблема, при использовании бинарного журнала в режиме Statement, может проявится, если на Slave сервере настроить запись в базы данных с именами, отличными от оригинала. Например, производится репликация одной БД с мастера db_countries на слейв, где эта же БД называется db_countries_slave (новое имя БД на Slave-сервере определяется параметром replicate-rewrite-db="db_countries->db_countries_slave", а для репликации уже назначается новое имя БД: replicate-do-db="db_countries_slave"). Пока на мастере производится обновление данных в БД с использованием USE db_countries и UPDATE names SET ..., все хорошо, но как только пройдет запрос, в котором будет указываться имя БД, например: UPDATE db_countries.names SET ... репликация на Slave останавливается с ошибкой: Table "db_countries.names" doesn"t exist" on query. Default database: "db_countries_slave". Query: UPDATE db_countries.names SET ... . В режиме ROW такой проблемы нет.
ROW - режим бинарного лога
ROW - при выборе этого способа хранения бинарного лога, в файл записывается исключительно изменения, для выбранных баз данных в двоичном формате. Данные могут занимать намного больше места, чем при режиме Statement. Но у этого вида репликации есть одно самое главное преимущество - в этом режиме репликация происходит намного безопаснее, чем при Statement.
В бинарный лог записываются только изменённые данные для тех баз данных, которые определены с помощью параметров binlog-do-db или binlog-ignore-db. База данных по умолчанию не влияет на это поведение. Благодаря этому, после запросов из примера 1 данные об обновлении попадут в бинарный лог, а вот sql из второго примера уже не будет записан.
Более подробное описание достоинств и недостатков режимов Statement и Row можно почерпнуть из официальной документации на английском: 17.1.2.1 Advantages and Disadvantages of Statement-Based and Row-Based Replication .
MIXED - режим бинарного лога
MIXED - режим, в котором бинарный лог одновременно использует 2 режима репликации: Statement и Row для хранения данных о различных запросах. Более подробно узнать, как работает режим бинарного лога Mixed можно из официальной документации на английском: 5.4.4.3 Mixed Binary Logging Format . Нельзя сказать, что это идеальный вариант, но если понимать, как работает Mixed, то его вполне можно применять на практике.
Автоматическая очистка бинарного лога - expire_logs_days
По умолчанию, бинарные логи никогда не очищаются автоматически. Для автоочистки log-bin служит параметр expire_logs_days, в котором задается кол-во дней, которое MySQL будет хранить бинарный журнал.
Пример автоматического удаления бинарного лога, с даты создания которого прошло более 10 дней
expire_logs_days= 10
Другие полезные настройки бинарного лога
Пользователь для подключения Slave к Master
При Master-Slave репликации, необходима минимум одна учетная запись пользователя на Master-сервере, которая будет использоваться Slave для подключения. Требования к правам доступа такого аккаунта: единственная привилегия REPLICATION SLAVE - открывать доступы к базам данным, таблицам или добавлять любые другие привилегии - не нужно. Один пользователь с REPLICATION SLAVE может использоваться разными подчиненными серверами для одновременного получения данных с главного сервера, или можно для каждого подчиненного создать отдельного пользователя.
Не стоит применять для репликации учетную запись наделенную любыми расширенными правами доступа. Логин и пароль для подключения к главному серверу хранится в открытом виде на подчиненном (файл master.info в каталоге с БД).
mysql>
CREATE
USER
"replicat"
@"10.0.0.1"
IDENTIFIED BY "pass"
;
mysql>
GRANT
REPLICATION SLAVE ON
*
.*
TO
"replicat"
@"10.0.0.1"
;
IP-адрес 10.0.0.1 - это ip Slave-сервера, нужно заменить на реальный. В sql-запросах можно заменить IP-адрес на специальный символ %, тогда подключиться к мастеру можно будет с любого хоста, но из соображений безопасности, лучше ограничится реальным адресом подчиненного сервера.
Дополнительные настройки
Для максимально корректной репликации баз данных, в которых используются таблицы типа InnoDB и транзакции, необходимо добавить такие строки в конфигурацию Master-сервера (my.cnf секция ):
innodb_flush_log_at_trx_commit=
1
sync_binlog=
1